FLP不可能原理
Fischer、Lynch和Patterson三位科学家于1985年发表的论文《Impossibility of Distributed Consensus with One Faulty Process》指出:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法(No completely asynchronous consensus protocol can tolerate even a single unannounced process death)。
也就是说在异步分布式系统中,不存在一个在任何场景下都能实现共识的算法。
以上结论被称为FLP不可能原理。该定理被认为是分布式系统中重要的原理之一。
CAP原则
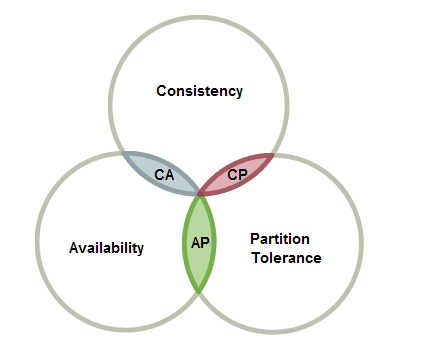
C(Consistency)、A(Availability)、P(Partition tolerance),即一致性、可用性、分区容忍三者最多只能同时满足两项。
该理论是由加州大学的计算机科学家 Eric Brewer 在1998年提出。由Gilbert and Lynch给出了证明。
假设有一个简单的分布式系统,有两台服务器G1,G2,两台服务器的数据是一致的,现有数据V,它的值是v0。现在有客户端client,整体结构如下:

Consistency
Every read receives the most recent write or an error
任何写操作之后的读操作访问分布式系统的每个节点,返回的值都是最新的结果。
举例来说,就是client向G1发送请求将V修改为v1,client在查询G1、G2,得到的结果是v1,我们称这个系统是一致的。
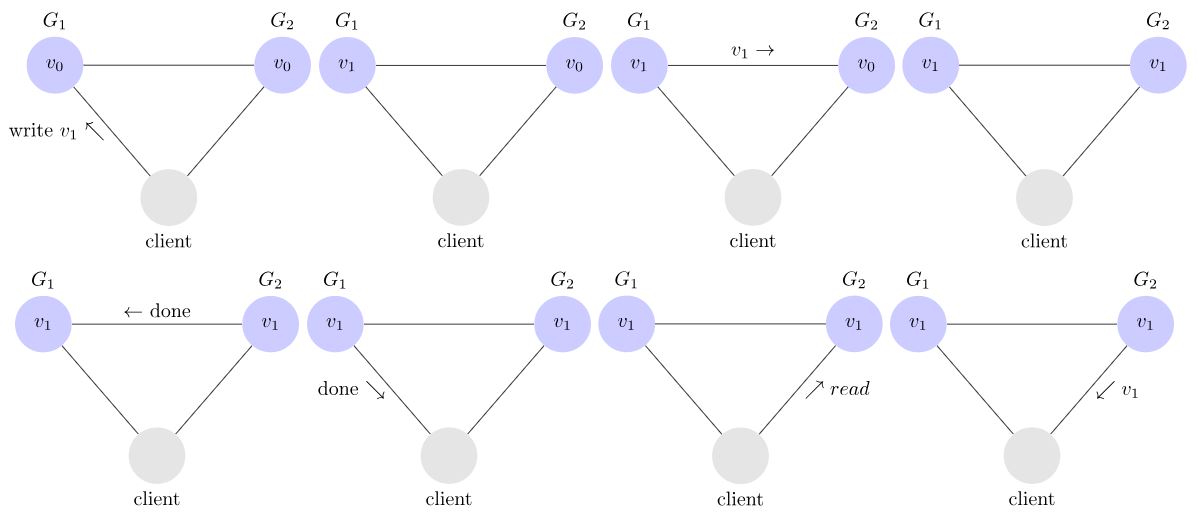
我们注意到,当G1的V改变后,为了使G2的值保持一致,G1向G2发送了一条信息,对V进行了修改。
如果client向G1发送请求将V修改为v1,client在查询G2,得到G2的值为v0,则这个系统是不一致的。
Availability
100% availability, for both reads and updates
对系统读写100%可用
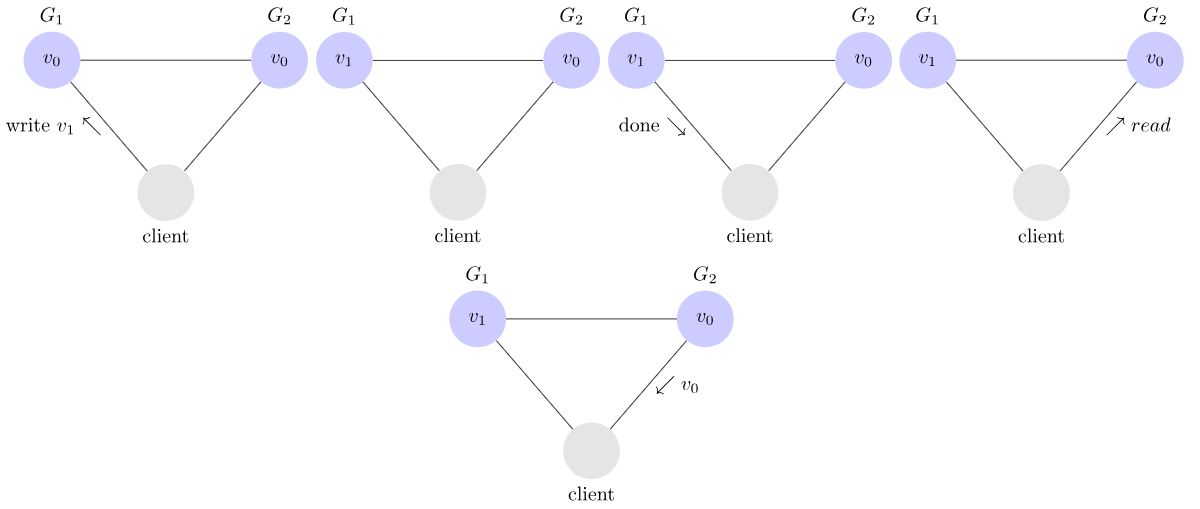
举例来说,当G1、G2发送网络分区时(即G1、G2网络中断),client可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。
Partition tolerance
tolerance to network partitions
能容忍一个节点间的网络分区。
举例来说,就是G1 和 G2 网络通信丢失信息,最坏的情况下,G1 和 G2完全隔离,我们的应用有能力正常工作。
CAP原理实例
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三项中的两项。
以数据库为例说明下CAP原理:
单实例
如MySQL、memcached、redis等,是一个单例模式,所以不存在“网络分区”、“不一致”, 但单点故障后会导致整个数据库瘫痪,所以可用性不能保证。也就是舍弃了“A”,保证了“C”和“P”。
分片Sharding
相比于单实例,多了一个节点去分割数据,总数据只有一份,一致性“C”得到保证,节点间不需要通信,分区容忍“P”得到保证,但任意节点宕掉时,会丢失一部分数据,“A”无法保证,和单实例版一样,只能保证“CP”。
这种情况下CAP各项指标虽然没有提升,但单服务器宕机只会导致服务降级;集群有了扩容缩容的可能性。Redis的slots,Cassandra的patitions,MongoDB的shards等都属于此类。
多副本写入
对于读操作,因为可用访问两个节点中的任意一个,所以可用性“A”提升了。
对于写操作,有三种情况:
- 同步更新。需要两个节点都更新成功才返回。这样一旦发生网络分区故障,写操作便不可用,牺牲了“A”。
2.异步更新。 即写操作直接返回,不需要等待节点更新成功,节点异步地去更新数据。这样可能由于网络故障导致数据不一致,即牺牲了“C”来保证“A”。 - 折衷。更新部分节点成功后便返回。强一致“C”则会牺牲部分“A”,弱一致“C”则牺牲“C”保证“A”。
集群Clustering
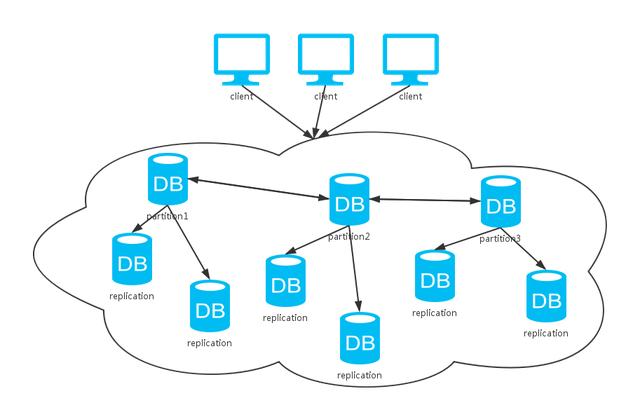
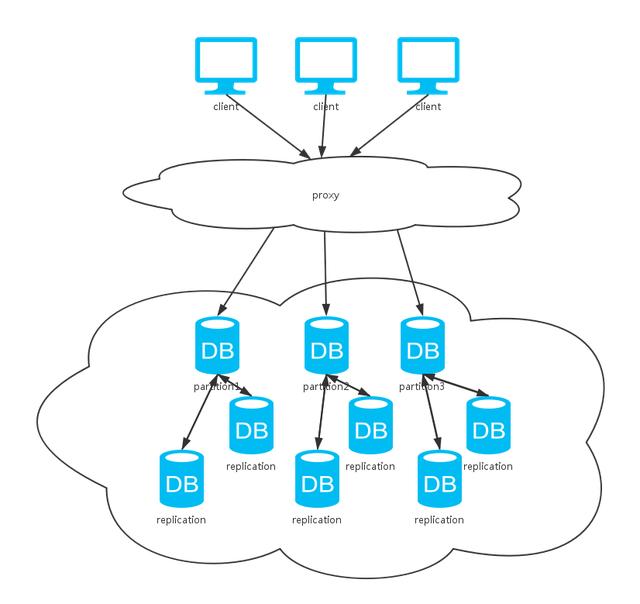
集群主要有两种模式如上。模式一需要写入多个副本才能成功返回,这种方式一致性( C )依旧是保证的。 但写入可用性( A )和分区可容忍性( P )相对于单机均会下降。换来的是:
- 较为简单的API,客户端不用关注“多写”问题;
- 读取操作的高可用(HA)。
由于上述方案是强一致性( C )的,这种应用场景常见于金融系统,这种这方面典型的代表有:ZooKeeper (KV数据库)、Vertica (列存储式数据库)、Aster Data (关系型数据库)、Greenplum (关系型数据库)
模式二类似”Sharding”中我们采用的方案,生产环境线上的数据库也往往采用放弃一定的一致性( C ) ,来提高可用性( A )和分区可容忍性( P )。
由于大多数互联网公司的需求不是要求强一致性( C ), 所以通过放弃一致性,达到更高的可用性( A )和分区可容忍性 ( P )成了目前市面上大多数NoSQL数据库的核心思想。
| 放弃CAP定理 | 说明 |
|---|---|
| 放弃P | 一种较为简单地做法是将所有的数据(或者仅仅是那些与事务相关的数据)都放在一个分布式节点上。这样的做法虽然无法100%地保证系统不会出错,但至少不会碰到由于网络分区带来的负面影响。需要注意的是放弃了“P”意味着放弃系统的可扩展性。 |
| 放弃A | 其做法是一旦系统遇到网络分区或其他故障时,那么收到影响的服务需要等待一定的时间,因此在等待期间系统无法对外提供正常的服务,即不可用。 |
| 放弃C | 放弃一致性,不是完全不需要数据一致性,而是放弃数据的强一致性,而保留数据的最终一致性。这样的系统无法保证数据保持实时的一致性,但是能够承诺的是,数据最终会达到一个一致的状态。具体多久能够达到数据一致取决于系统的设计,主要包括数据副本在不同节点之间的复制时间长短。 |
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
软状态( Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
最终一致性( Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
参考:
https://zhuanlan.zhihu.com/p/35608244
http://www.ruanyifeng.com/blog/2018/07/cap.html
https://mwhittaker.github.io/blog/an_illustrated_proof_of_the_cap_theorem/
https://my.oschina.net/yangjiannr/blog/1529185
https://blog.csdn.net/kevin_loving/article/details/80655345
Eric Brewer,Spanner, TrueTime & The CAP Theorem